背景
xxl-job 当中有一张表,数据量大概240W。 语句非常简单
SELECT count(*) FROM xxl_job_info
执行时间却要20S左右
相关表
在xxl-job 当中有一张表,如下:
CREATE TABLE `xxl_job_info` (
`id` int NOT NULL AUTO_INCREMENT,
`job_group` int NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 'GLUE源代码',
`glue_remark` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint NOT NULL DEFAULT '0' COMMENT '下次调度时间',
`trigger_no` bigint unsigned NOT NULL DEFAULT '0' COMMENT '当前任务最后的调度批次-初始化0',
`biz_type` varchar(8) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT 'default' COMMENT '业务类型',
KEY `tgnxtm_idx` (`trigger_status`,`trigger_next_time`,`trigger_last_time`) USING BTREE,
KEY `jg_idx` (`job_group`),
KEY `add_tm_idx` (`add_time`) ,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
MySQL版本
MySQL 8.0
数据量
240W 左右
问题
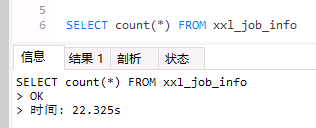
如下sql 执行非常的慢,耗时22秒
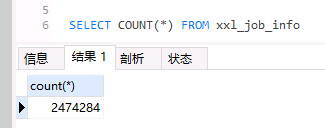
SELECT count(*) FROM xxl_job_info
分析问题
首先,这个count(*) 语句非常的简单,没有任何条件,只是简单的进行一个全表统计。这样的语句,效率低,是反直觉的,为了搞清楚这个问题,于是进行了一些探索和尝试。
优化思路1:尝试 count(*) 改写 count(1) [失败]
首先能想到的就是这个古老的传说,先跑一次看看效果:
SELECT count(1) FROM xxl_job_info
执行结果如下:
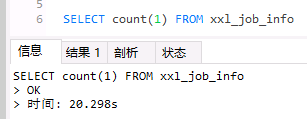
可见改写成count(1)没有效果,依然很慢。 其实MySQL个官方针对这个问题进行了说明:
https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
大意是:
InnoDB以相同的方式处理SELECT COUNT(*)和SELECT COUNT(1)操作。没有性能差异。
执行 EXPLAIN 查看执行计划
执行:
EXPLAIN SELECT count(*) FROM xxl_job_info
结果:

在执行计划中,这里使用了jg_idx这个索引。同时,在MySQL官方文档中,也能查找到相应的文档:
https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count
InnoDB processes SELECT COUNT() statements by traversing the smallest available secondary index unless an index or optimizer hint directs the optimizer to use a different index. If a secondary index is not present, InnoDB processes SELECT COUNT() statements by scanning the clustered index.
大意是:
InnoDB通过遍历最小的可用辅助索引(二级索引)来处理SELECT COUNT()语句,除非索引或优化器提示指示优化器使用其他索引。如果不存在辅助索引(二级索引),InnoDB将通过扫描聚集索引来处理SELECT COUNT()语句。
然而,即使使用了二级索引,在200W左右的数据量下,耗时20S也是不应该的。 于是,想起MsSQL精创选错索引,我们会用 一些WHERE条件语句进行引导。虽然这里执行计划显示是使用了jd_idx这个索引,但是感觉实际上内部执行有一些问题。
优化思路2:加引导条件
于是进行了SQL的改写:
SELECT count(*) FROM xxl_job_info where job_group >= 0
改写后的语句,只是在 WHERE条件后面加上了 job_group >= 0 这个条件,实际上 job_group 只有0和1这两个值,所以其实按理说加与不加,结果是相同的。这里的作用只是引导MySQL走这个 jd_idx索引。 执行结果如下:
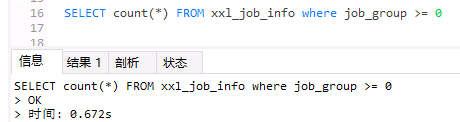
可以看到,这里的执行效率高了几十倍,最终只用了0.6秒就完成了全表的统计。
为什么会导致这样的结果
查询了很多资料,包括MySQL官方资料,以及网络上的已有资源。都没有找到相关的解释。这里只是猜想:
- 是否是MySQL内部执行逻辑的问题,导致与执行计划不匹配。
- 是否是实际统计走了 聚簇索引,导致统计效率低下。
- 是否是 job_goup >0 这个条件,让MySQL在缓存的读策略上有所不同,导致执行效率大大提高。
这里只做分享,如果遇到类似问题,能通过这种手段进行优化。如果有大神了解其内部原理,望赐教!